Introduction
It can come in quite handy to scrape data off a webpage and generate some interesting facts from it. Perhaps we’re working on the next big predictive model we plan to leverage to beat our friends in Fantasy Football. Or maybe we intend to scrape stock data from a finance website and get rich off trading penny stocks. But in reality, we’re mostly curious about how many games were made for the Nintendo 64.
Required tech
- python (I use 2.7 for this example)
- beautifulsoup
Data Source
Everyone knows that all the data on Wikipedia is 100% accurate, and there has never been an instance of said data containing any errors. Thus, we will use it for our little project. Since the Nintendo 64 is a device responsible for consuming much of my childhood I want to learn a little more about it. Visit the N64 Wikipedia page to learn more about the data we’re interested in.
Let’s get to work
First we need to get the data from the webpage. We can use requests to do this quite easily. We can get the data by executing the following code:
<pre class="wp-block-syntaxhighlighter-code">
import requests
from bs4 import BeautifulSoup
url = "https://en.wikipedia.org/wiki/List_of_Nintendo_64_games"
r = requests.get(url)
html = r.text
</pre>
The get method pulls the source code of the webpage and stores it in r. By utilizing text we convert the source code into a unicode object which we can use to parse the retrieved html. Now that we’ve got the source code we can use BeautifulSoup to parse it. Let’s see how many tables we can find on the webpage.
<pre class="wp-block-syntaxhighlighter-code">
soup = BeautifulSoup(html, "html.parser")
table = soup.find_all('table')
print(len(table))
>> 4
</pre>
Narrowing it down
We see there are four html tables on the Wiki page. Since we are interested in only the one that contains the game data we need to find a way to narrow it down to just that one table. One easy way is to check and see if the table has a CSS class or id that differs from the rest, and in this case it does. In most browsers you can right click the table and click Inspect. You should see something similar to:
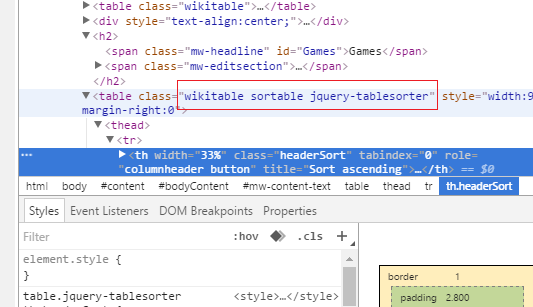
Look at the source code to find the correct table (contents of the red rectangle).
Once that’s done we modify the code a bit and give it a shot to see if we got our table:
table = soup.find_all('table', class_="sortable")
print(len(table))
>> 1
Great! So we’ve got the table we’re interested in and now we stored it in table. An alternative method would be to iterate through all four tables and check the table header tags but I’d rather just focus the remaining code on one table.
It’s parsing time!
To start let’s build a dictionary whose keys are the table headers of the html table. Let’s first investigate the values themselves:
for row in table[0].findAll('th'):
print('%r' % row.text)
>> u'Title(s)\n[10][11][12][13]'
>> u'Year first released\n[10][11][14][15]'
>> u'Developer\n[14][16]'
>> u'Publisher\n[10][11][14][17][18]'
>> u'Regions released\n[10][11][12][13][19]'
>> u'Number of players\n[10][12][13][20]'
>> u'ESRB/\nELSPA rating\n[10][17][21]'
>> u'Genre\n[10][11][15][18][22][23]'
As we can see those are some messy keys, so let’s clean them up.
n64_template = OrderedDict()
for row in table[0].findAll('th'):
key = row.text.split('\n')
key = key[0].replace('/', '').replace(' ', '_').lower()
n64_template[key] = None
print(n64_template)
>> OrderedDict([(u'title(s)', None), (u'year_first_released', None), (u'developer', None), (u'publisher', None), (u'regions_released', None), (u'number_of_players', None), (u'esrb', None), (u'genre', None)])
All this code does is clean up the keys and make them a bit more memorable and readable. We replace spaces(‘ ‘) with underscores(‘_’), make them lowercase, and remove an erroneous backslash. Now we’ve got a dictionary we can load with table data as follows:
ls = []
i = 0
for td in table[0].findAll('td'):
if i == 0:
dct = copy.copy(n64_template)
dct[key_order[i]] = td.text
i += 1
elif i in range(1, len(n64_template)-1):
dct[key_order[i]] = td.text
i += 1
elif i == 7:
dct[key_order[i]] = td.text
i = 0
ls.append(dct)
This is some quick and dirty code I threw together to load the data. All it does is recognize there are eight columns in the table and it loads the table row by row into the dictionary template we created above.
Explore the data
Now that all the data is loaded I just chose a few things I was interested in and parsed through the various topics, mainly by just counting things up with loops…nothing special here.
stats = {'total_number': len(ls),
'total_na_released': 0,
'developer_list_count': {},
'publisher_list_count': {},
'year_first_released_na_count': {},
'esrb_na_count': {}}
for item in ls:
# fix possible error
if u'\u2014' in item['esrb']:
item['esrb'] = item['esrb'].split(u'\u2014')[0]
if not item['esrb']:
item['esrb'] = 'no_rating'
# get number of released games in NA
if 'NA' in item['regions_released'] and item['year_first_released'] != 'Cancelled':
stats['total_na_released'] += 1
# get number of games released in NA each year
if item['year_first_released'] not in stats['year_first_released_na_count']:
stats['year_first_released_na_count'][item['year_first_released']] = 1
else:
stats['year_first_released_na_count'][item['year_first_released']] += 1
# get esrb count for NA
if item['esrb'] not in stats['esrb_na_count']:
try:
stats['esrb_na_count'][item['esrb']] = 1
except KeyError:
print('a', item['esrb'])
stats['esrb_na_count'][item['esrb']] = 1
else:
try:
stats['esrb_na_count'][item['esrb']] += 1
except KeyError:
print('b', item['esrb'])
stats['esrb_na_count'][item['esrb']] += 1
# get a count of how many games each developer produced in all regions
if item['developer'] not in stats['developer_list_count']:
stats['developer_list_count'][item['developer']] = 1
else:
stats['developer_list_count'][item['developer']] += 1
# get a count of how many games were published by each company in all regions
if item['publisher'] not in stats['publisher_list_count']:
stats['publisher_list_count'][item['publisher']] = 1
else:
stats['publisher_list_count'][item['publisher']] += 1
# keep only developers/publishers that made more than 6 games
stats['developer_list_count'] = {key: stats['developer_list_count'][key] for key in stats['developer_list_count'] if stats['developer_list_count'][key] &amp;amp;gt; 6}
stats['publisher_list_count'] = {key: stats['publisher_list_count'][key] for key in stats['publisher_list_count'] if stats['publisher_list_count'][key] &amp;amp;gt; 6}
for key in stats:
print(key, stats[key])
>> ('developer_list_count', {u'Eurocom': 8, u'Acclaim': 8, u'Rare': 11, u'Paradigm Entertainment': 7, u'Iguana Entertainment': 16, u'Hudson Soft': 13, u'Konami': 29, u'Nintendo': 15, u'Midway': 8, u'Electronic Arts': 10})
>> ('total_number', 388)
>> ('publisher_list_count', {u'Acclaim': 26, u'Imagineer': 7, u'Infogrames': 7, u'Kemco': 7, u'Hudson Soft': 11, u'THQ': 16, u'Midway': 38, u'Konami': 29, u'Activision': 12, u'Crave Entertainment': 9, u'Nintendo': 58, u'Titus Software': 7, u'Ubisoft': 11, u'Electronic Arts': 25})
>> ('esrb_na_count', {u'E/': 47, u'M/15+': 21, u'T/3+': 4, u'E/11+': 9, u'T/15+': 12, u'M/': 1, u'M/18+': 4, u'E/-': 1, u'eC/': 2, u'M/11+': 2, u'T/': 11, u'K-A/3+': 32, u'T/11+': 27, u'E/3+': 120, u'K-A/': 2, u'K-A/11+': 1})
>> ('year_first_released_na_count', {u'1997': 38, u'1996': 9, u'1999': 99, u'1998': 75, u'2002': 1, u'2000': 66, u'2001': 8})
>> ('total_na_released', 296)
Summary
According to the table we can get some fun facts that I summarized below:
- There were 388 total games released or cancelled in all regions for the N64.
- There were 296 total games released in NA for the N64.
- In 1999 the largest number of games were created. All years are shown in a graph below.
- Nintendo only developed 15 games for the N64, though they published 58.
- Based on the pie chart below, it’s clear the N64 made more kid friendly games than anything else.
- Midway developed the most games with 38.
- Konami published the second most games with 29.
- Only 1 game was published in the final year of 2002: Tony Hawk’s Pro Skater 3.
- In no particular order, my favorite games were:
- Diddy Kong Racing
- Mario Kart 64
- GoldenEye 007
- Banjo-Kazooie
- Super Mario 64
- Star Fox 64
Number of games released each year for North America.
Just over 65% of games were made for kids or everyone.
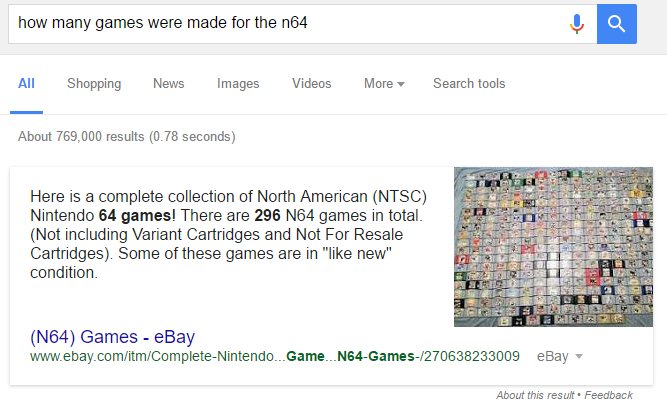
I asked Google how many games there were and they responded with an Ebay posting that matched the Wikipedia data!
Conclusion
Hopefully you’ve now got a basic understanding of how to scrape a table from a website, and you’ll be able to use the technique on your own personal projects. One day I plan on doing a blog where we use a spider to crawl a website and do something fun with it. Beautifulsoup is a really powerful module and it makes webpage scraping very straightforward and enjoyable. Not as enjoyable as my time spent on the N64 as a kid…but enjoyable nonetheless 🙂
Project Code
<pre class="wp-block-syntaxhighlighter-code">
from collections import OrderedDict
import copy
import requests
from bs4 import BeautifulSoup
# get the source code of the website
url = "https://en.wikipedia.org/wiki/List_of_Nintendo_64_games"
r = requests.get(url)
html = r.text
# turn the source code into soup
soup = BeautifulSoup(html, "html.parser")
table = soup.find_all('table')
print(len(table))
# get the table we're interested in
table = soup.find_all('table', class_="sortable")
print(len(table))
# build a dictionary we can use to store data in
n64_template = OrderedDict()
key_order = []
for col in table[0].find_all('th'):
key = col.text.split('\n')
key = key[0].replace('/', '').replace(' ', '_').lower()
n64_template[key] = None
key_order.append(key)
print(n64_template)
# load the data in
ls = []
i = 0
for td in table[0].findAll('td'):
if i == 0:
dct = copy.copy(n64_template)
dct[key_order[i]] = td.text
i += 1
elif i in range(1, len(n64_template)-1):
dct[key_order[i]] = td.text
i += 1
elif i == 7:
dct[key_order[i]] = td.text
i = 0
ls.append(dct)
#for item in ls:
# print(item)
stats = {'total_number': len(ls),
'total_na_released': 0,
'developer_list_count': {},
'publisher_list_count': {},
'year_first_released_na_count': {},
'esrb_na_count': {}}
for item in ls:
# fix possible error
if u'\u2014' in item['esrb']:
item['esrb'] = item['esrb'].split(u'\u2014')[0]
if not item['esrb']:
item['esrb'] = 'no_rating'
# get number of released games in NA
if 'NA' in item['regions_released'] and item['year_first_released'] != 'Cancelled':
stats['total_na_released'] += 1
# get number of games released in NA each year
if item['year_first_released'] not in stats['year_first_released_na_count']:
stats['year_first_released_na_count'][item['year_first_released']] = 1
else:
stats['year_first_released_na_count'][item['year_first_released']] += 1
# get esrb count for NA
if item['esrb'] not in stats['esrb_na_count']:
try:
stats['esrb_na_count'][item['esrb']] = 1
except KeyError:
print('a', item['esrb'])
stats['esrb_na_count'][item['esrb']] = 1
else:
try:
stats['esrb_na_count'][item['esrb']] += 1
except KeyError:
print('b', item['esrb'])
stats['esrb_na_count'][item['esrb']] += 1
# get a count of how many games each developer produced in all regions
if item['developer'] not in stats['developer_list_count']:
stats['developer_list_count'][item['developer']] = 1
else:
stats['developer_list_count'][item['developer']] += 1
# get a count of how many games were published by each company in all regions
if item['publisher'] not in stats['publisher_list_count']:
stats['publisher_list_count'][item['publisher']] = 1
else:
stats['publisher_list_count'][item['publisher']] += 1
# keep only developers/publishers that made more than 6 games
stats['developer_list_count'] = {key: stats['developer_list_count'][key] for key in stats['developer_list_count'] if stats['developer_list_count'][key] &amp;amp;gt; 6}
stats['publisher_list_count'] = {key: stats['publisher_list_count'][key] for key in stats['publisher_list_count'] if stats['publisher_list_count'][key] &amp;amp;gt; 6}
for key in stats:
print(key, stats[key])
</pre>
Leave a Reply